New Generations of BERT
Most modern large language models (LLMs) use the decoder-only Transformer structure coupled with auto-regressive (AR) generation scheme. In other words, they generate text one token at a time, with each new token predicted based on all previously generated tokens. Nowadays, when people talk about and adopt Transformers, they are mostly referring to this framework.
However, you might remember that before the introduction of GPT3, BERT framework was the star of the show, and it provides a completely different formulation of Transformers: BERT is encoder-only with Masked Language Model (MLM) generation scheme. In other words, BERT randomly masks certain tokens in the input and predicts them based on the surrounding context from both directions.
Despite BERT failing to dominate LLMs, they are still highly relevant, both in the NLP domain and in other domains. For the NLP domain, decoder-only structure is fundamentally not suitable for calculating text embeddings (which extends to downstream tasks like RAG), and BERT-like structure is preferred. For other domains, there are also many scenarios where the BERT framework is more suitable. For example, when the data is not inherently sequential, when the task needs bidirectional blank in-filling instead of unidirectional step-by-step generation, or you want to build a multi-task method instead of a pure generative method.
In this post we will take a look at a few recent works aiming to modernize BERT, bringing latest advancement in LLMs to the "classic" BERT framework.
Note that I am more interested in adopting those methods to domains other than NLP, thus will ignore the technical details that are only applicable in the NLP domain (e.g., text datasets used for training). I will also be focusing on common design choices that appear in all four existing works listed above.
Positional Encoding
Transformers inherently are not sensitive to sequential orders. Positional encoding was introduced in the original Transformer paper to explicitly inject absolute order information into the Transformer.
$$ PE_{(pos,2i)} = \sin(pos/10000^{2i/d_{\text{model}}}) $$
$$ PE_{(pos,2i+1)} = \cos(pos/10000^{2i/d_{\text{model}}}) $$
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
There are limitations of this encoding, the most apparent one being it cannot generalize to sequences longer than those in the training set. This is especially problematic for LLMs, since you will want to generate sentences longer than those in the training set.
Thus, LLMs nowadays mostly use RoPE (rotary positional embeddings) or its variants. In contrast to positional encoding which is a type of absolute position embedding, RoPE is a type of relative position embedding. Below is the formulation of RoPE in the 2D space given in the RoFormer paper.
$$f_{\{q,k\}}(x_m, m) = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} W_{\{q,k\}}^{(11)} & W_{\{q,k\}}^{(12)} \\ W_{\{q,k\}}^{(21)} & W_{\{q,k\}}^{(22)} \end{pmatrix} \begin{pmatrix} x_m^{(1)} \\ x_m^{(2)} \end{pmatrix}$$RoFormer: Enhanced transformer with Rotary Position Embedding (2024). Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng.
Replacing the vanilla positional encoding with RoPE is a common design choice in modernized BERT. This can bring the benefit of easy context extension to BERT.
Activation Function
Vanilla BERT mostly used the GeLU activation function. Over the years people have been developing improved activation functions that are proven to improve overall performance over GeLU. Two of the more widely adopted ones include SwiGLU and GeGLU.
$$ \text{GLU}(x, W, V, b, c) = \sigma(xW + b) \otimes (xV + c) $$
$$ \text{GeGLU}(x, W, V, b, c) = \text{GeLU}(xW + b) \otimes (xV + c) $$
$$ \text{SwiGLU}(x, W, V, b, c, \beta) = \text{Swish}_\beta(xW + b) \otimes (xV + c) $$
GLU variants improve transformer (2020). Shazeer, Noam.
These are basically free performance improvement to BERT.
Normalization
Vanilla BERT uses the original Transformer layer normalization design: a layer normalization is applied after each residual connection. Some modernized BERT models used alternative designs called pre-layer normalization, which moves the normalization layer inside the residual connections.
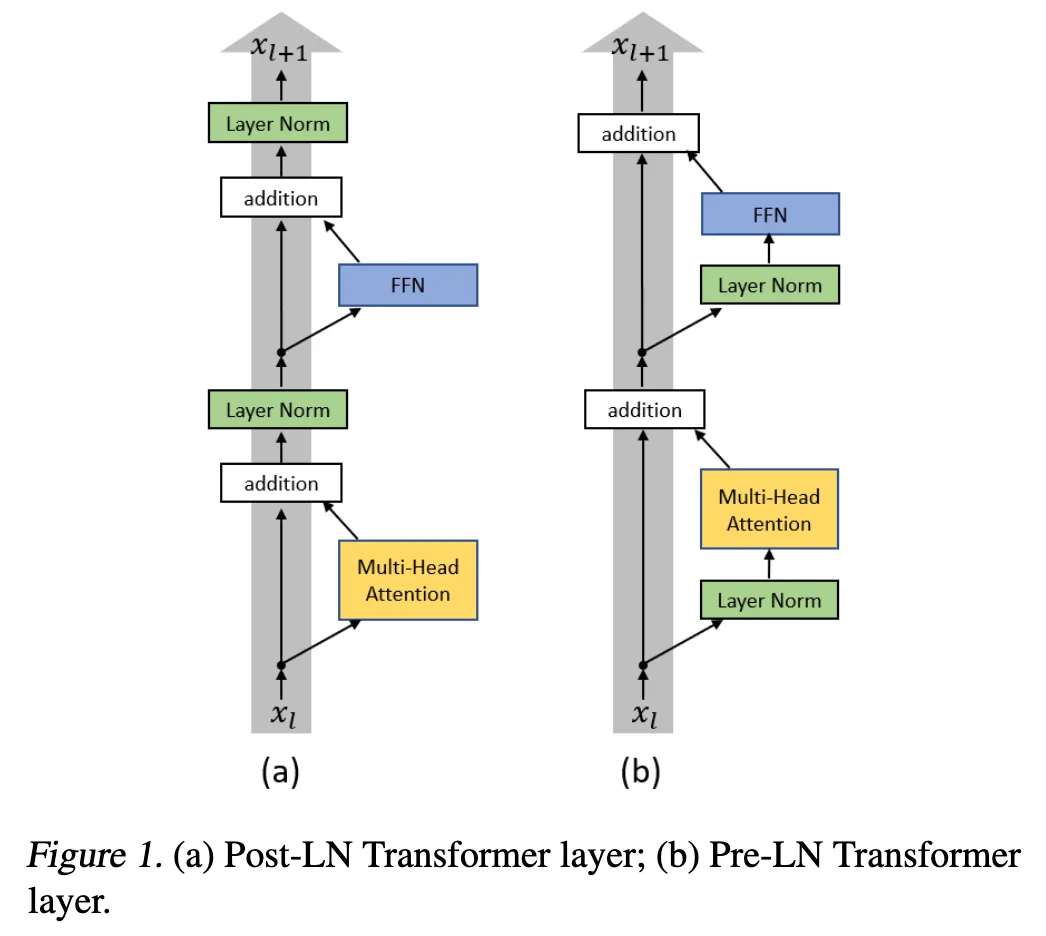
On layer normalization in the transformer architecture (2020). Xiong, Ruibin and Yang, Yunchang and He, Di and Zheng, Kai and Zheng, Shuxin and Xing, Chen and Zhang, Huishuai and Lan, Yanyan and Wang, Liwei and Liu, Tieyan.
While this design choice might not introduce much performance improvement, it is proven to stabilize training and allow for higher learning rate.
Pre-training
Vanilla BERT has two pre-training tasks: masked language model (MLM) and next sentence prediction (NSP). The MLM task randomly masks tokens in the input sequence (replacing the masked tokens with a special [MASK] token); the NSP task predicts whether two input sentences are consecutive in the original text or randomly paired.
First and foremost, most modernized BERT models preserve the MLM task, but drop the NSP task, as it is proven to actually have no performance benefit.
Another aspect of improvement is how the masked tokens are selected. Vanilla BERT masks 15% of tokens in an input sequence, a design choice that has been proven not optimal. Thus, most modernized BERT models increase the mask portion to 20% or higher.
Should you mask 15% in masked language modeling? (2023). Wettig, Alexander and Gao, Tianyu and Zhong, Zexuan and Chen, Danqi.
If you were to train BERT to perform generative tasks, randomly masking and recovering tokens in input sequences might not be enough, and you should consider more generation-oriented pre-training tasks. An intuitive design is an AR-like generation task where a long and consecutive sub-sequence is fully masked and set for recovering.
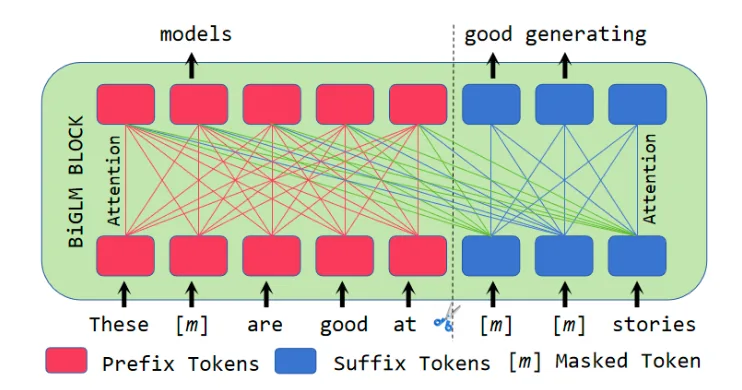
Unveiling the Potential of BERT-family: A New Recipe for Building Scalable, General and Competitive Large Language Models (2025). Xiao, Yisheng and Li, Juntao and Hu, Wenpeng and Luo, Zhunchen and Zhang, Min.
Efficiency Improvement
Seeing the insane computational load required by LLMs, there are lots of techniques introduced that can improve the computational efficiency or training stability of Transformers over the years, and most of them can be applied to BERT. I won't go deep into their technical details here, so I will just list them and give a brief introduction as follows.
- Flash Attention: A memory and compute efficient attention implementation that provides optimized kernels for transformer models
- Sequence Packing: A technique that packs multiple sequences into a single training example to avoid high minibatch-size variance and ensure batch size uniformity
- Optimizers: AdamW is a widely adopted optimizer that decouples weight decay from the gradient update; StableAdamW is a variant that further improves upon AdamW by adding Adafactor-style update clipping as a per-parameter learning rate adjustment
- Learning Rate Schedule: A modified trapezoidal (Warmup-Stable-Decay) schedule with a short warmup period, constant learning rate for the majority of training, and a decay phase at the end
- Batch Size Schedule: Gradually increases batch size during training from smaller to larger values; this can accelerate training progress by updating weights more frequently in early stages with smaller batches.
References:
- Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference (2025). Warner, Benjamin and Chaffin, Antoine and Clavié, Benjamin and Weller, Orion and Hallstr"om, Oskar and Taghadouini, Said and Gallagher, Alexis and Biswas, Raja and Ladhak, Faisal and Aarsen, Tom and Adams, Griffin Thomas and Howard, Jeremy and Poli, Iacopo.
- NeoBERT: A Next Generation BERT (2025). Breton, Lola Le and Fournier, Quentin and Morris, John Xavier and Mezouar, Mariam El and Chandar, Sarath.
- Nomic Embed: Training a Reproducible Long Context Text Embedder (2025). Nussbaum, Zach and Morris, John Xavier and Mulyar, Andriy and Duderstadt, Brandon.
- Unveiling the Potential of BERT-family: A New Recipe for Building Scalable, General and Competitive Large Language Models (2025). Xiao, Yisheng and Li, Juntao and Hu, Wenpeng and Luo, Zhunchen and Zhang, Min.