Train LLMs to Understand Beyond Text
One of the "missing pieces" to build an AI agent for a specific domain, like the spatiotemporal domain I mentioned in this post, is to enable LLMs' understanding of data other than text, so that the feedback loop can be closed. The problem essentially comes down to building a multi-modal LLM which can take (or even produce) data other than text.
There are of course lots of existing successful techniques developed and adopted to solve this general problem, especially for images. In this post I touched on the topic of multi-modal LLMs, but focused on how to feed multi-modal data into LLMs (from an input embedding standpoint). This post will be more focused on a higher-level: how to train an LLM so that it actually understands multi-modal data, with images as the primary example.
Train on Data-Text Pairs
The most straight-forward method to bridge multi-modal data and text is to train an LLM with pairs of data and text. And spoiler: This step is basically inevitable, at least at current state of AI.
For images, it is relatively easy to find a large-scale image dataset where each image is coupled with a text description. For example, you can scrape images from Wikipedia which often contain descriptions, or from social media where users write descriptions.
There are some practices that you can improve efficiency of this training step. You do not necessary have to train an LLM from scratch, instead, you can train only the adaption layer between a pre-trained image encoder (like CLIP) and a text-only pre-trained LLM, like the design in LLaVA as shown below.
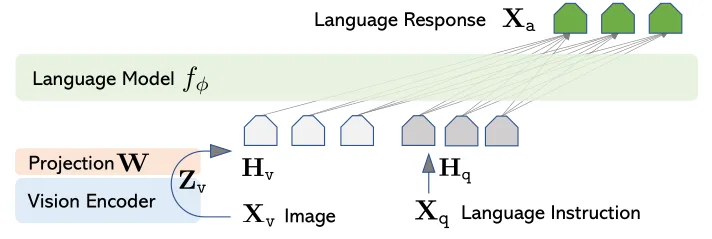
Liu, Haotian, et al. "Visual instruction tuning." Advances in neural information processing systems 36 (2023): 34892-34916.
Still, if we only rely this training step, we will be needing a lots of data and text pairs, which is challenging even for images, let alone other types of multi-modal data.
Expand Data-Text Pair Datasets
If you have at least a few data-text pairs to begin with, there are methods to expand it so that the LLM can be better trained.
You can first train a smaller LLM with available data-text pairs at hand, then use it to generate more descriptions on unlabeled data. For example, with limited image-text pairs, you can first train a image descriptor, and apply it on unlabeled images to generate more image-text pairs. Images without text descriptions have much higher availability compared to those with.

Li, Junnan, et al. "Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation." International conference on machine learning. PMLR, 2022.
Even crazier, you can train a new or use an off-the-shelf conditioned diffusion model that can generate images given descriptions. It should be relatively easy to make up descriptions using text-only LLMs.

Ma, Feipeng, et al. "Image captioning with multi-context synthetic data." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 5. 2024.
Based on the idea of instruction-tuning that is widely use to train LLMs, LLaVA proposed a solution to augment text descriptions that can also improve the trained LLM's ability to follow instructions. The core idea is that a text-only LLM can be used to generate various specific questions regarding an image (and the corresponding answer), given the image's:
- Original text description
- Description of bounding boxes, as a textual representation of the spatial relationships of objects

Liu, Haotian, et al. "Visual instruction tuning." Advances in neural information processing systems 36 (2023): 34892-34916.
Or you can understand this practice as: letting a text-only LLM understand the content of an image, without actually giving the LLM the image.
Self-supervising to Help
There are also self-supervising/pre-training techniques that can be used to help with training the model, even without any data-text pairs (at least in the pre-training stage).
You can try to apply the vast available self-supervising methods that have been developed over the years to see if they will help. DINOv2 applied simple self-supervising methods, like contrastive learning and mask recovery, on pure image datasets when pre-training a multi-modal LLM. It is reported that self-supervision is actually better at learning general representations of images compared to training on image-text pairs, and can help with the later stage alignment between images and text.
Oquab, Maxime, et al. "Dinov2: Learning robust visual features without supervision." Trans. Mach. Learn. Res. (2024).
STIC also demonstrates an interesting implementation of self-supervised learning: Use LLMs to generate positive and negative (less preferred) captions of the same image, which can then be used to perform contrastive learning or direct preference optimization (DPO).
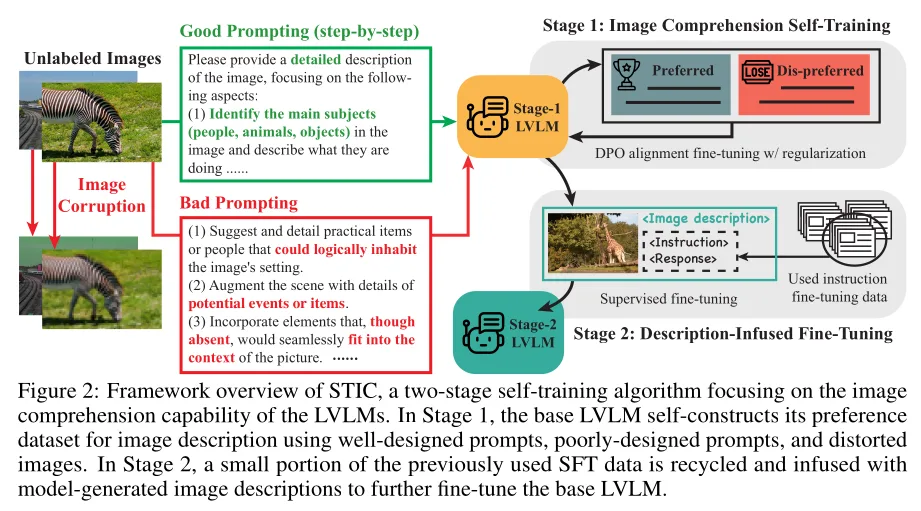
Deng, Yihe, et al. "Enhancing large vision language models with self-training on image comprehension." Advances in Neural Information Processing Systems 37 (2024): 131369-131397.
Nevertheless, at least in current stage of AI, to align the embeddings of multi-modal data and text, having a certain amount of data-text pairs is necessary, even with self-supervising techniques that can be applied without text.
Side Note
Here a work that is not directly related to the topic of this post, but I feel my takeaway is worth discussing within the context of this post.
DeepSeek-OCR is a recently published and very interesting work. The core idea is, when feeding text input into LLMs, compared to directly using the text, it is actually more token-efficient to paste the text into a Word document, take a screenshot, and feed the image to LLMs.
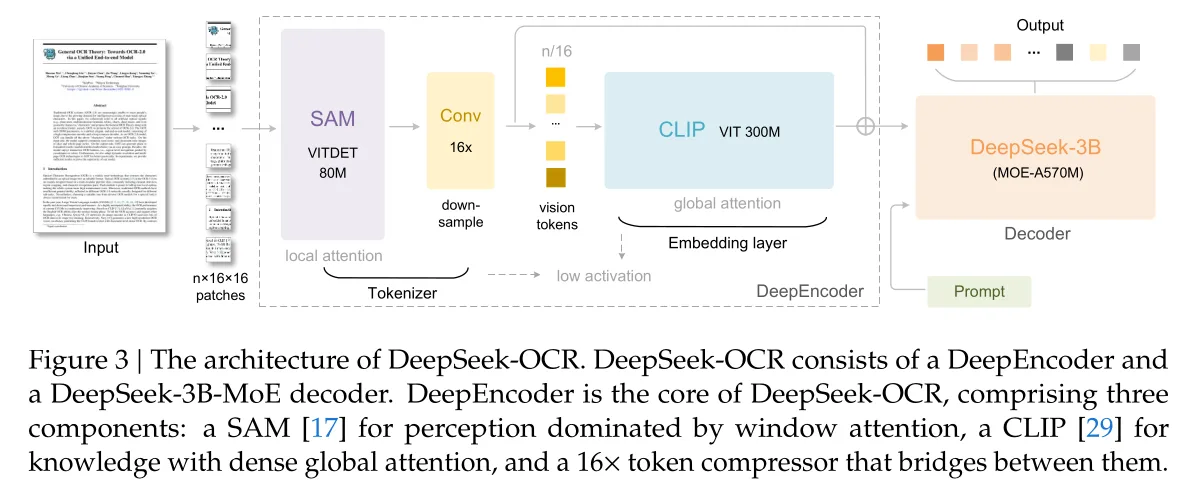
Wei, Haoran, Yaofeng Sun, and Yukun Li. "DeepSeek-OCR: Contexts Optical Compression." arXiv preprint arXiv:2510.18234 (2025).
My takeaway from this paper is: Maintaining multi-modal data in native (or compressed native) representations is more token-efficient than text descriptions, when the task requires preserving fine-grained information. In that case, even if you can describe all information contained in the original data using plain text, it is probably less efficient than the native representations, seeing that text is not even efficient enough to represent itself in LLMs.
I also saw another takeaway of the work that the reason images can represent text more efficiently than text itself is: Images are continues and text is discrete. Thus, images' embedding space can be "denser". Well, most multi-modal data that cannot be directly interpreted by LLMs are primarily composed of continuous modality, so my takeaway still holds true.