Advanced APIs in the Era of AI
TL;DR: Advanced API patterns and techniques enable high-performance, real-time, and message-driven communication essential for modern AI systems—like subscription services that deliver continuous updates rather than requiring individual requests.
In API Fundamentals we established the three pillars of APIs and learned how to interact with them using basic HTTP methods. While these fundamentals work well for simple request-response patterns, modern AI systems demand more sophisticated communication approaches. Consider how sending a letter and waiting for a response works for occasional communication, but becomes impractical when you need continuous updates—like sending hourly request letters to a weather service instead of receiving automatic daily forecasts.
Example: When you send a request to OpenAI/Anthropic's API, you wait for a few seconds for the complete response to appear. However, when you interact with ChatGPT/Claude on their official web/mobile app, their responses are continuously streamed to you word-by-word. In reality, the streaming behavior is also achievable through APIs.
In this module, we'll explore advanced API techniques that enable more flexible communication patterns especially relevant for modern AI systems. We'll start with additional fundamentals like rate limiting and versioning, then move to implementing streaming and message-driven protocols. We'll also touch on the shiny new star of AI communication protocols--model context protocol. Finally, we'll examine architectures that make it possible to process high-throughput data efficiently.
Additional Fundamentals
Before exploring advanced protocols, let's examine some additional fundamental concepts that we encountered in the previous module but didn't explore in depth. These concepts are particularly relevant for AI APIs.
API Versioning
As we've established, APIs are essential means of communication in the digital world, and most API-based interactions happen automatically—you wouldn't expect there to be a human behind the millions of API requests and responses happening every second. The premise of the digital world working correctly by itself is that the specifications of each API are consistent. Yet, it is also impractical that we never have to update the APIs to incorporate new features or make changes, especially for AI services where new features and updates to AI models are constantly introduced. API versioning is a process to tackle this dilemma.
API versioning is the practice of managing different iterations of APIs, allowing providers to introduce changes and new features without breaking existing interactions. Think of it like maintaining backward compatibility—old systems continue working while new features become available in newer versions.
There are a few common versioning strategies you will witness when exploring existing AI APIs.
URL path versioning is the most straightforward approach, embedding version information directly in the endpoint URL. For example, https://api.example.com/v1/generate versus https://api.example.com/v2/generate. This makes the version immediately visible and easy to understand. You probably have noticed that both OpenAI and Anthropic use this versioning approach.
Header-based versioning keeps URLs unchanged by specifying versions through HTTP headers like API-Version: 2.1 or Accept: application/vnd.api+json;version=2. This approach is more flexible but less transparent.
Query parameter versioning uses URL parameters such as ?version=1.2 or ?api_version=latest. While simple to implement, it can clutter URLs and may not feel as clean as other approaches. This approach also doesn't fit nicely with the REST standard we introduced before.
Model-specific versioning is particularly relevant for AI services, where different model versions (like gpt-3.5-turbo vs gpt-4o) represent distinct capabilities. This is usually specified with a key in the request body.
Rate Limiting
As its name suggests, rate limiting is a strategy implemented by API providers to control the number of requests processed within a given time frame. Rate limiting is particularly important in AI services because advanced AI models are computationally expensive, and without proper limits, a few heavy users could overwhelm the entire service. You might not have encountered rate limiting during practice in the previous module since usage costs typically hit budget limits first. However, understanding rate limiting becomes crucial when scaling applications.
Rate limiting strategies vary across providers, with different rules typically applied to different AI models and user tiers. Take a look at OpenAI and Anthropic's rate limiting strategies for reference. Generally speaking, there are a few types of rate limiting:
- Request-based: X requests per minute/hour, common for many APIs
- Token-based: Limit by input/output tokens, common for conversational AI services where processing power is directly related to the number of tokens used
- Concurrent requests: Maximum simultaneous connections, more frequently seen in data storage services
- Resource-based: GPU time or compute units, common for cloud computing services
There are also different algorithms for determining when the rate limit is hit and recovered:
- Fixed window: A fixed limit within specific time frames (e.g., 100 requests per minute, reset every minute). Easy to implement but can cause traffic spikes at window boundaries.
- Sliding window: Continuously calculates usage based on recent activity, providing smoother request distribution and preventing burst abuse.
- Token bucket: Allows requests only when tokens are available in a virtual "bucket," with tokens replenished at a fixed rate. This allows short bursts while maintaining overall rate control.
Videos:
Note: We will get a more concrete understanding of API versioning and rate limiting later in Module 3: Wrap AI Models with APIs when we have to implement these strategies ourselves.
Advanced API Protocols
With these fundamentals in mind, let's explore advanced protocols that enable more sophisticated communication patterns.
Streaming Protocols
Returning to the example at the beginning, word-by-word streaming is achievable through APIs using streaming protocols. Such protocols are widely supported in conversational AI APIs, since most AI models for conversation are grounded in next token prediction (NTP) architecture, and they fit the natural way humans read text. We will take a look at two prominent streaming protocols: Server-Sent Events (SSE) and WebSocket.
Server-Sent Events
Server-Sent Events (SSE) enables a client to receive a continuous stream of data from a server, and is the technique used by most conversational AI services (chatbots) to stream text word-by-word to users. SSE is lightweight and easy to adopt since it is based on the HTTP protocol, but it only supports unidirectional communication from one application to another. SSE starts when a receiver application opens a connection to the sender application, with the sender responding and keeping the connection open. The sender then sends new data through the connection and the receiver automatically receives it.
Below is an example of enabling SSE-based streaming extending the code in API Fundamentals:
import os
import requests
import json
url = "https://api.anthropic.com/v1/messages"
headers = {
"x-api-key": os.getenv("API_KEY"),
"Content-Type": "application/json",
"Accept": "text/event-stream", # Accept SSE format
"User-Agent": "SomeAIApp/1.0",
"anthropic-version": "2023-06-01"
}
json_body = {
"model": "claude-sonnet-4-20250514",
"max_tokens": 2048,
"temperature": 0.7,
"stream": True, # Enable streaming
"messages": [
{
"role": "user",
"content": "Explain the concept of APIs."
}
]
}
try:
response = requests.post(
url,
headers=headers,
json=json_body,
timeout=30,
stream=True # Enable streaming in requests
)
response.raise_for_status()
print("Streaming response:")
for line in response.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith('data: '):
data = line[6:] # Remove 'data: ' prefix
if data == '[DONE]':
break
try:
event_data = json.loads(data)
# Extract and print the content delta
if 'delta' in event_data and 'text' in event_data['delta']:
print(event_data['delta']['text'], end='', flush=True)
except json.JSONDecodeError:
continue
print("\nStreaming complete!")
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")The key differences from the regular POST request are:
"stream": Truein the request body to enable streaming"Accept": "text/event-stream"header to specify SSE formatstream=Trueparameter inrequests.post()to handle streaming responses- Using
response.iter_lines()to process the continuous stream of data - Parsing the SSE format where each chunk starts with
data:
See it work in action:
Extended Reading: Take a look at the official documents for streaming messages from OpenAI and Anthropic, which provide different approaches towards implementing SSE-based text streaming.
WebSocket
You might have played with ChatGPT's voice mode where you can talk with ChatGPT and interrupt it, just like phone calling someone in real-world. This is unachievable with unidirectional protocols like SSE. Instead, it can be achieved through bidirectional streaming protocols such as WebSocket.
Unlike SSE which is built on top of HTTP, WebSocket is a communication protocol of its own. For two applications to establish a WebSocket connection, one application first sends a standard HTTP request with upgrade headers, while the other application agrees to upgrade and maintains the connection through the WebSocket lifecycle. To create a WebSocket connection in Python, we no longer can use the requests package since it is specifically built for HTTP. Instead, we have to use websocket package. Below is a basic example of connect to OpenAI's real-time API:
import os
import json
import websocket
OPENAI_API_KEY = os.getenv("API_KEY")
url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-12-17"
headers = [
"Authorization: Bearer " + OPENAI_API_KEY,
"OpenAI-Beta: realtime=v1"
]
def on_open(ws):
print("Connected to server.")
# Send a request to the API when the connection opens
payload = {
"type": "response.create",
"response": {
"modalities": ["text"],
"instructions": "Say hello!"
}
}
ws.send(json.dumps(payload))
def on_message(ws, message):
data = json.loads(message)
print("Received event:", json.dumps(data, indent=2))
ws = websocket.WebSocketApp(
url,
header=headers,
on_open=on_open,
on_message=on_message
)
ws.run_forever()
Videos:
Extended Reading: WebRTC is another real-time protocol that provides peer-to-peer connections between applications. Compared to WebSocket which is more suitable for connections between servers or between a server and a client, WebRTC excels at streaming data between clients without relying on server architectures, and is widely used in video calling and live streaming softwares.
Message-driven Protocols
While streaming protocols excel at delivering continuous data between applications—similar to two people communicating through phone calls—there are scenarios where data from multiple applications needs to be distributed to multiple other applications, like journalists producing newsletters for a publisher who then delivers them to subscribers. Direct communication between each application would be impractical in such cases. This is where message-driven protocols come into play. We will introduce MQTT (Message Queuing Telemetry Transport) as a representative message-driven protocol, and take a look at Apache Kafka as a comprehensive message-driven system.
MQTT
MQTT (Message Queuing Telemetry Transport) is a publish-subscribe message protocol designed for resource-constrained devices like low-power computers and smart home devices. It operates on the publish-subscribe (pub-sub) pattern, where publishers send messages on specific topics without knowing who will receive them, while subscribers express interest by subscribing to specific topics. MQTT requires brokers to operate—devices or applications that receive messages from publishers and deliver them to subscribers. MQTT has various applications in IoT (Internet of Things) communications and can be utilized in AI systems where its pub-sub pattern is needed.
To implement MQTT in Python, you can use the paho-mqtt library and a public broker like the HiveMQ at broker.hivemq.com. Below is an example implementation of publishers and subscribers. Both can be run as multiple instances on multiple devices.
# publisher.py
import paho.mqtt.client as mqtt
broker = 'broker.hivemq.com'
port = 1883
topic = 'demo/ai-systems'
client = mqtt.Client()
client.connect(broker, port)
client.publish(topic, 'This is a very important message!')
client.disconnect()# subscriber.py
import paho.mqtt.client as mqtt
def on_message(client, userdata, message):
print(f"Received: {message.payload.decode()} on topic {message.topic}")
broker = 'broker.hivemq.com'
port = 1883
topic = 'demo/ai-systems'
client = mqtt.Client()
client.connect(broker, port)
client.subscribe(topic)
client.on_message = on_message
client.loop_forever()Apache Kafka
Similar to MQTT, Apache Kafka also follows the pub-sub pattern to deliver messages. Unlike MQTT, Kafka is a comprehensive computing system that goes beyond a protocol and is capable of handling large amounts of messages with low latency.
Conceptually, Kafka is composed of three types of applications: producers (similar to MQTT's publishers), consumers (similar to MQTT's subscribers), and brokers. Their respective roles are very similar to those in MQTT. As a high-performance system, Kafka is usually built on top of a clustering architecture, where multiple computers work together to avoid system overload and maintain consistent speed even with messages produced at high rates. Due to its performance advantages, it is used in many large-scale IT infrastructures such as Netflix and Uber for streaming and processing real-time events.
Implementing a Kafka system with Python is a bit complicated. Usually you need to run ZooKeeper (Apache's clustering management system) and Kafka nodes separately, since Kafka's Python library kafka-python only provides interfaces to actual Kafka nodes. Once you have those set up, implementing producers and consumers is similar to implementing publishers and subscribers in MQTT. Below is an example implementation of producers and consumers.
# producer.py
import os
from kafka import KafkaProducer
import json
import time
# Create a Kafka producer
producer = KafkaProducer(
bootstrap_servers=f"{os.getenv('KAFKA_ADDRESS')}:9092",
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# Produce messages
for i in range(10):
message = {'number': i, 'message': f'Hello Kafka! Message {i}'}
producer.send('demo/ai-systems', value=message)
print(f'Produced: {message}')
time.sleep(1)
# Ensure all messages are sent
producer.flush()
producer.close()
print("All messages sent successfully!")# consumer.py
import os
from kafka import KafkaConsumer
import json
# Create a Kafka consumer
consumer = KafkaConsumer(
'demo/ai-systems',
bootstrap_servers=f"{os.getenv('KAFKA_ADDRESS')}:9092",
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='demo-consumer-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)
print("Waiting for messages...")
# Consume messages
for message in consumer:
message_value = message.value
print(f'Consumed: {message_value}')Videos:
Model Context Protocol
Recent advancements in conversational AI models—large language models (LLMs)—have shown great potential in solving complex tasks. Their utilization is highly dependent on the comprehensiveness of the information they are given and the diversity of actions they can perform. When you interact with LLMs through the conversation APIs we introduced earlier, you can manually feed as much information as possible into the conversation context and instruct LLMs to tell you what to do in natural language. However, this process doesn't align with the philosophy of APIs: it is neither automatic nor reproducible, which means it cannot scale to production-level applications. The Model Context Protocol (MCP) addresses this challenge.
MCP was introduced by Anthropic in 2024 and has rapidly become the standard for conversational AI models to integrate with external information sources and tools. Built on JSON-RPC 2.0—the same foundation as other protocols we've explored—MCP provides a standardized approach that eliminates the need for custom integrations between every AI system and external service. While similar functionality could be achieved through hardcoded custom interactions using conventional API techniques, MCP's widespread adoption stems from its development simplicity and standardized approach.
MCP's architecture is composed of three types of applications: hosts, servers, and clients. Hosts are AI applications that users interact with directly, such as Claude Code and IDEs. These applications contain LLMs that need access to external capabilities. Servers are external applications that expose specific capabilities to AI models through standardized interfaces. These might include database connectors, file system access tools, or API integrations with third-party services. Clients live within host applications and manage connections between hosts and servers. Each client maintains a dedicated one-to-one connection with a specific server, similar to how we saw individual connections in our previous protocol examples.
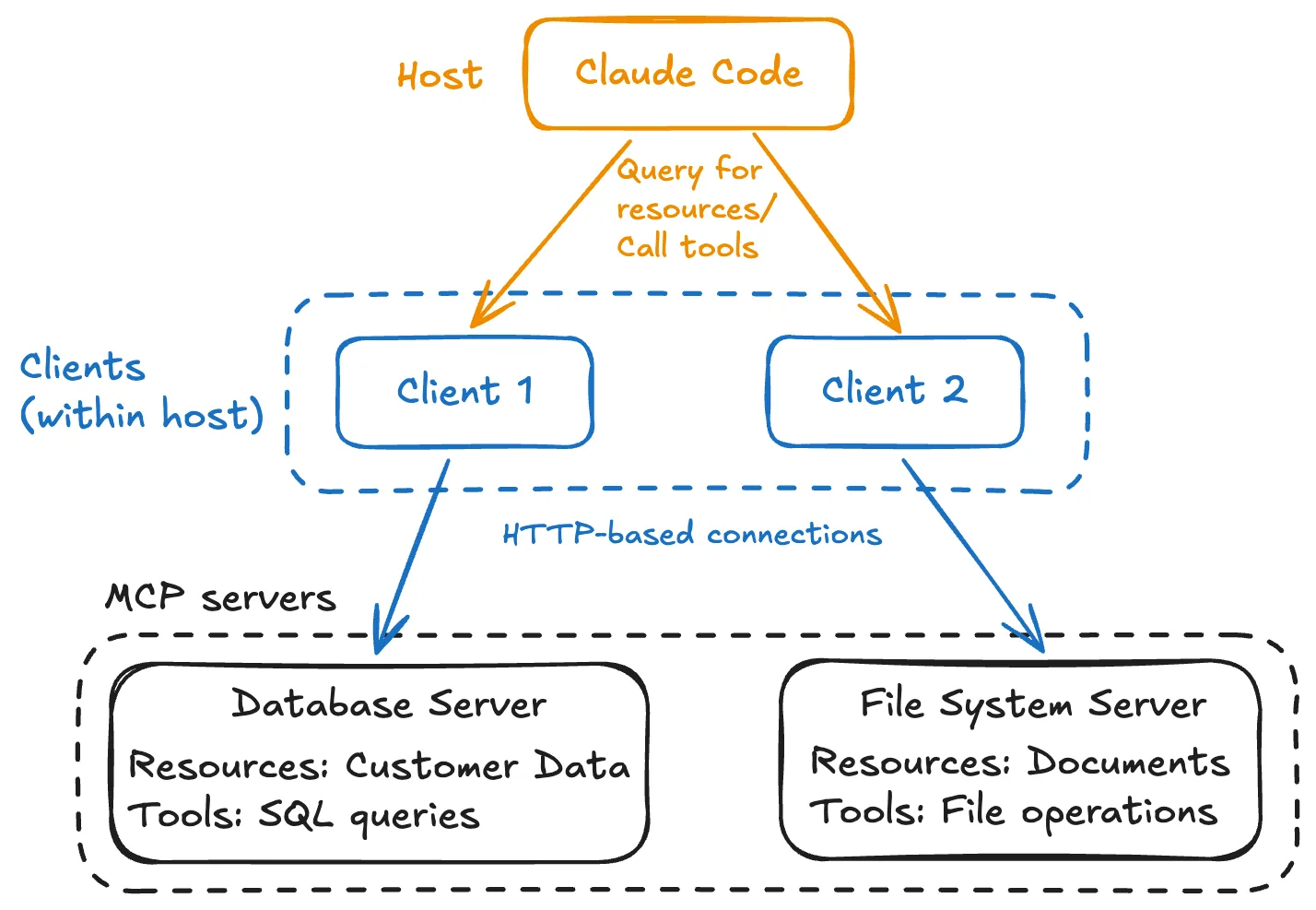
MCP servers can provide three types of capabilities to AI systems: resources, tools, and prompts. Resources act like read-only data sources, similar to HTTP GET endpoints. They provide contextual information without performing significant computation or causing side effects. For example, a file system resource might provide access to documentation, while a database resource could offer read-only access to customer data. Tools are executable functions that AI models can call to perform specific actions. Unlike resources, tools can modify state, perform computations, or interact with external services. Examples include sending emails, creating calendar events, or running data analysis scripts. Prompts are pre-defined templates that help AI systems use resources and tools most effectively. They provide structured ways to accomplish common tasks and can be shared across different AI applications.
MCP supports two primary communication methods depending on deployment needs: stdio (Standard Input/Output) for local integrations when clients and servers run on the same machine, and HTTP with SSE for remote connections—leveraging the same SSE protocol we explored earlier for streaming responses.
Implementing MCP servers and clients with Python is relatively straightforward. Examples of a weather server and an MCP client are provided in the official quick start tutorials.
Videos:
Extended Reading: https://modelcontextprotocol.io/specification/ provides complete technical details of MCP, while https://modelcontextprotocol.io/docs/ provides tutorials and documentations for building MCP servers and clients.
There are lots of public MCP servers run by major companies, such as Zapier and Notion. Feel free to take a look at lists of MCP servers:
- https://github.com/punkpeye/awesome-mcp-servers
- https://github.com/wong2/awesome-mcp-servers
Should you always use MCP for connecting LLMs with external resources and tools? Maybe not. Take a look at blog posts discussing this topic:
- https://lucumr.pocoo.org/2025/7/3/tools/
- https://decodingml.substack.com/p/stop-building-ai-agents
High-Performance Data Pipelines
Building on these protocol foundations, we now turn to the infrastructure needed to handle large-scale data processing. In production environments, protocols alone might be insufficient for processing massive datasets, potentially creating bottlenecks in AI systems. High-performance data pipelines address this challenge by providing the processing power needed for large-scale data operations. We've already examined one such system (Kafka) above. Here we'll explore two additional systems from Apache: Hadoop and Spark. While Kafka excels at delivering high-throughput messages, Hadoop and Spark are designed to analyze large-scale data with high speed and performance.
Apache Hadoop
Hadoop is a framework for storing and processing large amounts of data in a distributed computing environment (clustering). In essence, it is actually a collection of open-source software with the key idea of utilizing clustering architecture to handle massive amounts of data. Without going deep into its hardware infrastructure, there are two core layers in Hadoop: a storage layer called HDFS, and a computation layer called MapReduce.
Hadoop Distributed File System (HDFS) is the architecture for storing large amounts of data in a cluster. It breaks large files into smaller blocks (usually 128 MB or 256 MB) and stores them across multiple machines. Each block is replicated multiple times (typically 3) to ensure fault tolerance—a common clustering practice where a few node failures won't compromise data integrity. It's like buying three copies of a DVD and storing them in your house and your friend's house so you're unlikely to lose them.
MapReduce is the computation layer for efficiently processing large amounts of data in a cluster. Input data is divided into chunks and processed in parallel, with each worker processing a chunk and producing key-value pairs. These key-value pairs are then grouped to generate final results. Think of how big IT companies split a large software project into multiple modules for every employee to work on individually, then merge everyone's work into the final product. A common way to interact with Hadoop systems with Python is writing MapReduce jobs.
Apache Spark
While Spark and Hadoop are both designed for large-scale data workloads, they have distinct architectural approaches and differences in detailed functionalities.
To begin, unlike HDFS in Hadoop, Spark doesn't have its own native file system but can be integrated with external storage systems including HDFS or databases. This makes its implementation and deployment more flexible. Part of this flexibility comes from the fact that Hadoop relies on its HDFS data architecture, while Spark's storage efficiency is primarily achieved through storing intermediate data in memory rather than on disks, which is usually much faster.
Spark's computation architecture is also different from Hadoop. There are two key concepts: RDDs (Resilient Distributed Datasets) and the DAG (Directed Acyclic Graph) Scheduler. RDDs are essentially immutable collections of data that are distributed across a cluster of machines, similar to each job assigned to each employee that do not conflict with each other. The DAG scheduler is Spark's brain for figuring out how to compute the results, similar to how a management team figures out how to split a big project into multiple jobs. Spark has built-in APIs that support several programming languages to interact with its system, including Python with the pyspark library.
Videos:
Exercise
Upgrade the chatbot program you implemented in API Fundamentals to demonstrate the advanced API concepts covered in this module.
Exercise: Streaming Chatbot Enhancement
Upgrade your chatbot from API Fundamentals to implement streaming capabilities:
- SSE Implementation: Use Server-Sent Events as demonstrated in the Server-Sent Events section to receive responses word-by-word instead of waiting for complete responses
- Stream Processing: Parse the streaming response format and handle the continuous data flow appropriately, including proper handling of connection termination signals