AI Compute Hardware
TL;DR: Modern "AI computers" aren't fundamentally different: they still use the 80-year-old Von Neumann architecture. While CPUs excel at sequential processing, AI workloads need massive parallel computation and high memory bandwidth. This mismatch led to specialized hardware.
Unless you have been living off-grid for the last few years, you have probably been tired of hearing "AI computers" or something similar.




Despite those vendors trying to convince you that you need a new generation of computers to catch up with the AI hype. In the last year of WWII, John von Neumann introduced the Von Neumann architecture. 80 years later, most computers on Earth are still based on this architecture, including most so-called AI computers.
Admittedly, the capabilities of computer hardware have been growing rapidly ever since the architecture is introduced, and is one of the most important motivation and foundation for the development of AI models and systems. But for this course, we will need to start from the basics and take a look at the architecture that started everything.
Computer Architecture
In 1945, John von Neumann documented what would become the most influential computer architecture design in history: the Von Neumann architecture. This architecture established the foundation that still governs most computers today, from smartphones to supercomputers.
The below illustration shows the Von Neumann architecture. To help you understand the concepts in this architecture, we will use an analogy to a restaurant kitchen. Imagine a busy restaurant kitchen, with orders and recipes (instruction) coming by and ingredients (data) ready to be cooked. With chefs (CPU) following orders and recipes and prepare dishes, a pantry and a counter (memory unit) for storing ingredients and recipes, waiters (input/output devices) bringing in orders and deliver dishes, and corridors (bus) connecting all staff and rooms.
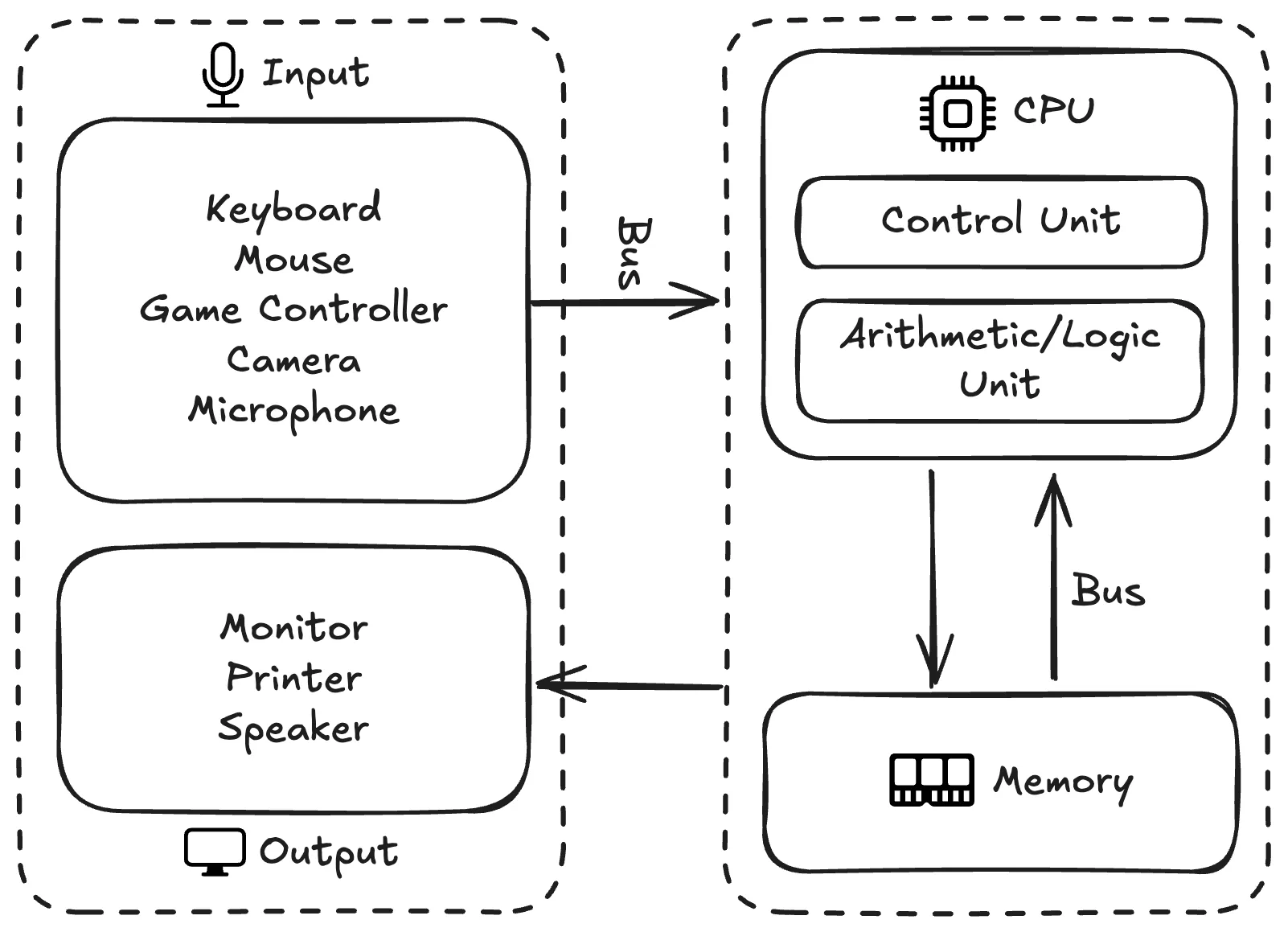
Instruction & Data
For a computer to finish a certain task, it needs two types of information: instruction and data.
Instructions tell the computer exactly what operations to perform, like recipes in a restaurant. A recipe is usually a step-by-step guide on how to handle the ingredients and cooking tools:
1. Cut onion into pieces
2. Heat up pan to medium heat
3. Add 2 tablespoons oil
4. Sauté onions until goldenInstructions are also step-by-step specification on how to handle and process data:
1. LOAD dkk_price
2. MULTIPLY dkk_price by conversion_factor
3. STORE result in usd_price
4. DISPLAY usd_priceThe computer also needs data itself, representing the information that needs to be processed, like ingredients in a restaurant. For the above recipe, you will need ingredients:
- 2 large onions
- Olive oilAnd the computer will need data:
- dkk_price: 599
- conversion_factor: 0.1570
- usd_price: to be calculatedCentral Processing Unit (CPU)
This is the brain of the computer, similar to the group of chefs in the restaurant. They can be composed of a variety types of sub-units, especially in modern CPUs, but here we will be focusing on two essential types: control unit (CU) and arithmetic logic unit (ALU).
Control unit (CU) is like the executive chef who reads orders and recipes, understands what needs to be done in order to fulfill the orders, and coordinates all the staff and equipment to perform each step of the process. To be more specific, CU is in charge of processes including: retrieving the next instruction from memory, interpreting the instruction's operation code and operands, and coordinating the execution by sending signals to other components.
Arithmetic logic unit (ALU) is like the chefs who do the actual cooking, processing ingredients following the commands from CU. ALU typically can handle a variety of computational operations including: arithmetic (addition, subtraction, multiplication, division), logical (AND, OR, NOT, XOR), comparison (equals to, greater than, less than), and bit manipulation (shifts, rotations, etc).
Memory
Memory is where both instructions and data are stored, like a comprehensive pantry where both ingredients and recipe books are stored. The memory will also have an address system, similar to the pantry having a unified shelving system so that all staff can more easily access it. More specifically, a memory system will have characteristics including: unified address space (both instructions and data use the same addressing scheme), random access (any memory location can be accessed directly in constant time), and volatile storage (contents are lost when power is removed).
Input/Output
An input/output (I/O) system manages communication between the computer and the external world, similar to waiters in the restaurant who bring in orders and deliver finished dishes. From an abstract standpoint, an I/O system will have I/O controllers for device management and protocol handling, and I/O methods for different types of interactions between I/O devices and the computer. From a physical standpoint, you have your common input devices like keyboard, mouse, trackpad, microphone, and camera, and output devices like monitor, speaker, and printer.
Bus
A bus system provides the communication pathways across all components in a computer, similar to the corridors in the kitchen for staff to move around, communicate with other staff, access different components, and carry cooking tools, ingredients, and dishes. Such system can be roughly categorized into three sub-systems: address bus (specifies the memory or I/O device location to access), data bus (carries actual data transferred between components), and control bus (carries control signals and coordinates different components).
Another analogy for any of you who have played Factorio (a factory management/automation game): for scalable production, you will usually also have a bus system connecting storage boxes, I/O endpoints, and machines actually producing or consuming stuff. Such system make it easy to add a new sub-system to existing ones.
Von Neumann Architecture in Practice
To showcase how this architecture is implemented in real-world, we will use the Raspberry Pi 5--a small yet complete computer--as an example.
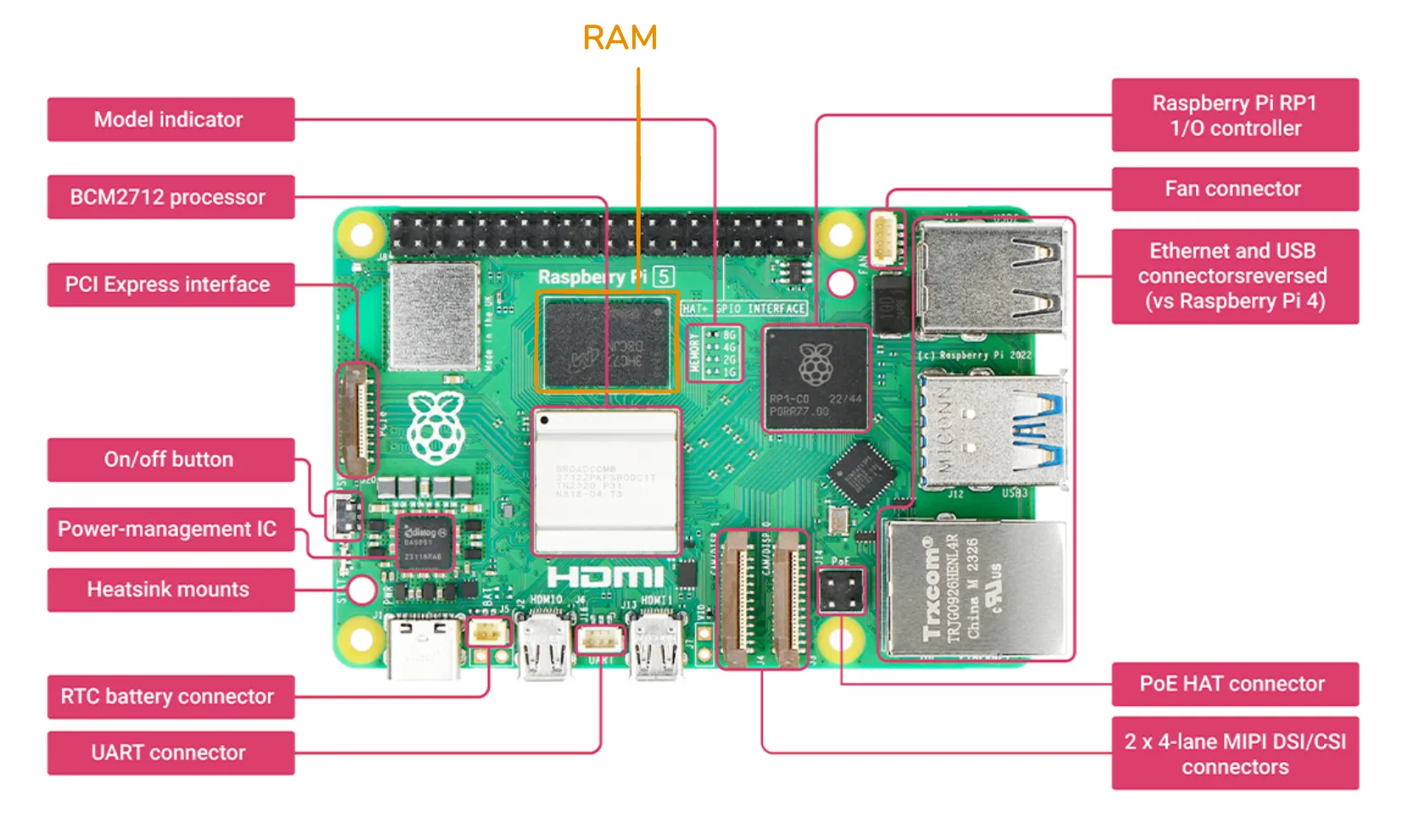
To start, we have CPU in the center-left of the board (labelled BCM2712 processor in the figure). Worth noting that like most modern CPUs, this CPU has multiple cores: like multiple chefs working together.
We then have the memory (labelled RAM in the figure), which you might notice is positioned very close to the CPU. This is to lower the access latency, similar to in the kitchen putting the counters closer means quicker access to the things chefs need.
There are also lots of I/O interfaces on the board, like the PCI Express interface for high-speed peripherals, the Ethernet and USB connectors, and the MIPI DSI/CSI connectors for connecting cameras. The connection between the Raspberry Pi and the I/O devices are also managed by the Raspberry Pi RP1 I/O controller.
And if you look very closely, you can see traces everywhere on the board, this is the physical implementation of the bus system. These traces are essentially copper wires connecting all components together.
Videos:
Limitations of Generic Hardware
As we mentioned, most modern computers still fundamentally adhere to the Von Neumann architecture. But there are indeed limitations of generic computing hardware, especially CPUs, for heavy AI workloads. And there are two major aspects that CPUs are not very suitable for AI computing.
Sequential Processing vs. Parallel Demands
CPUs excel at sequential processing, which means they can execute complex instructions one after another. Think of a university professor capable of solving complex math problems, who can solve any known problems thrown at them, but they can only solve one problem at a time. Of course, modern CPUs usually have multiple cores, but the number of cores usually sits around 8 for consumer tier and 64 for professional server tier.
On the other hand, AI models (especially neural networks) heavily rely on matrix-related computation. For example, matrix manipulation accounts for 45-60% of runtime in Transformer models in most large language models. Those manipulations usually only involve relatively simple instructions like add and multiply, but each manipulation includes thousands of independent calculations that could happen in parallel. Imagine given a thousand of simple equations to a professor to solve, each equation is very simple for the professor, but will still take a lot of time to solve all of them. A group (hundreds) of primary school students, though each incapable of solving complex equations, will probably be faster at dealing with these one thousand equations.
Memory Bus Bottleneck
Remember the bus system connecting different components in a computer? These buses are usually designed to be low latency, especially the bus between CPUs and memory chips. Since CPUs are usually in charge of executing complex instructions which involve fetching and storing data scattered in different locations of the memory, latency is a more important metric for CPUs.
However, as mentioned, AI models heavily rely on large-scale parallel instructions on matrices--usually stored in a relatively local block in memory, typical memory bus's advantage of low latency becomes disadvantage here, since a low latency memory bus usually comes with the downside of low bandwidth. In other words, the ability to move a large chunk of data quickly is a more critical metric for most AI models.
Specialized Hardware
The fundamental mismatch between CPU architecture and AI workload calls for specialized hardware to speed up AI computing. Essentially, we need hardware that excels in parallel processing and have high-bandwidth memory.
Graphics Processing Unit (GPU)
GPU is the representative type of hardware specialized for AI computing. You could tell from its name that it is originally designed for processing computer graphics. More specifically, it was originally designed in the 1980s to accelerate 3D graphics rendering for video games. Rendering a 3D video game involves calculation of lighting, shading, and texture mapping, and display millions of pixels, with highly optimized algorithms that breaks such calculation into small units that are composed of simple instructions and can be done in parallel.

To compute such algorithms more efficiently, GPUs are designed to excel at parallel processing. While a modern CPU usually features less than 100 powerful cores, a modern GPU usually contains thousands of weak cores. Each core can only handle simple instructions--just like a primary school student, but all the cores combined can finish a parallelized task much faster than a CPU.
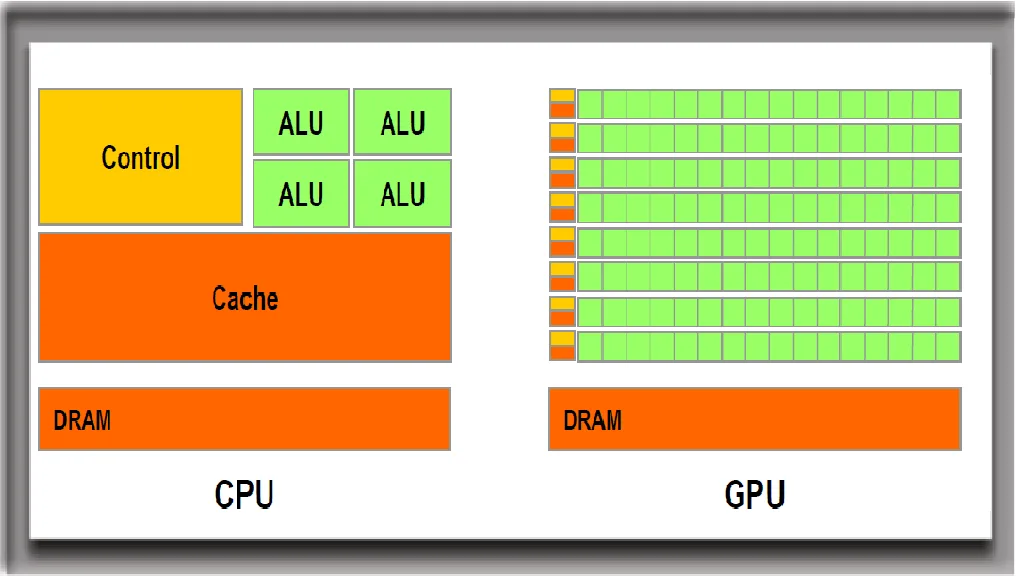
The memory on a GPU is also designed around high-bandwidth, so that large chunks of data can be accessed quickly. For example, the bandwidth of DDR memory for CPUs sits around 50 to 100 GB/s, while the GDDR memory for GPUs can deliver up to 1.5 TB/s bandwidth, and the HBM memory specifically designed for AI workloads can deliver up to 2 TB/s bandwidth.
Interestingly, the need for parallel processing and high-bandwidth of computer graphics aligns quite well with AI computing. Thus, GPU has become the dominant type of specialized hardware for AI workloads in recent years. Sadly this leads to major GPU brands don't give a sh*t about gamers and general consumers anymore.
Tensor Processing Unit (TPU)
Although GPU accidentally became perfect for AI workloads by repurposing computer graphics hardware, as the AI industry rapidly grows, companies are also trying to introduce hardware specifically designed for AI computing.
One example is Google's TPU. TPU adopts an architecture where thousands of simple processor cores aligned in a grid, and the incoming data and instructions flow through the grid like waves: each processor core does a small calculation and passes the result to its neighbors.
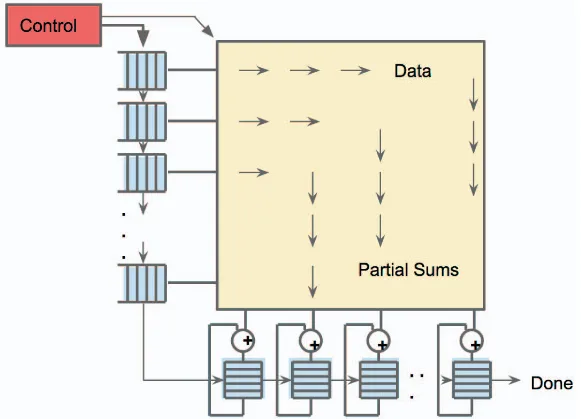
Hardware like TPUs is highly specialized in AI computing, which means they can be more efficient for AI workloads compared to GPU, which still need to handle graphics and other general computing tasks. However, this also means they are impractical for any other tasks. Nowadays TPUs are largely seen in data centers, especially those built by Google themselves.
Neural Processing Unit (NPU)
While TPUs target data centers and high-performance computers, with more and more integration of AI models in personal computing devices including PCs and smartphones (regardless of whether we want them or not), there is emerging hardware targeting those devices which emphasizes power efficiency. The specialized AI computing hardware in such devices is usually NPUs.
As mentioned, the goal of NPUs is to deliver AI computing acceleration while consuming minimal power and physical space. To achieve this, on top of the specialization of most AI computing hardware, they are also built around miniaturization: NPUs focus on running pre-trained models rather than training new ones, and they usually use low-precision arithmetic such as 8-bit or even 4-bit compared to the full 32-bit.
As for the specific architecture design, different companies have different designs. For example, Apple calls their NPUs Neural Engine, integrated into their smartphone chips from iPhone 8. Qualcomm calls their NPUs AI Engine, working collaboratively with the GPUs in their chips. Nowadays you will also see NPUs integrated into those so called "AI computers", such as in Apple's M4 desktop chip, AMD's Ryzen AI series laptop chip, and Qualcomm's Snapragon X Elite laptop chip.
Return to Von Neumann Architecture
Despite all the hyped-up specialized hardware for AI computing, most modern computers still fundamentally adhere to the Von Neumann architecture at the system level. Regardless of GPUs, TPUs, or NPUs integrated into computers, this hardware will still connect to CPUs via the bus system, share the unified memory address space, and is ultimately managed and coordinated by CPUs. The CPU remains the "executive chef" coordinating the system, while specialized processors act like highly skilled sous chefs handling specific tasks.
The Von Neumann architecture's genius lies not in its specific components, but in its modular design that continues to accommodate new types of processing units as computational needs evolve. Just like Factorio, while new assembly lines might need to be built to produce new types of products introduced by updates to the game, the bus system will remain the golden standard architecture if you want your factory to be scalable and productive.
Videos:
Exercise
Run an AI model on different types of hardware provided by Google Colab.
Spin up Google Colab, an interactive playground (essentially Jupyter Notebook) for running Python code with different types of hardware (CPU, GPU, and TPU) and enough free computing hours for us to play with.
Have fun tinkering around with an AI model on it and try out different types of hardware:
- Run the image analysis model we used in Wrap AI Models with APIs.
- Calculate the theoretical size of the model (hint: can be achieved by calculating the number of parameters in the model).
- Change your runtime to different types of hardware (CPU, GPU, and TPU) and rerun the model.
- Record the time the model needs to process one image and compare the time across different types of hardware.