High Availability & Reliability
TL;DR: When your service goes down, users leave. Learn how to measure availability with industry-standard metrics (MTBF, MTTR), and implement practical strategies like redundancy and backups to keep your AI API running reliably.
In October 2025, millions of people worldwide woke up to find ChatGPT unresponsive. Snapchat wouldn't load. Fortnite servers were down. Even some banking apps stopped working. All thanks to a single issue in an AWS data center that cascaded across hundreds of services. For over half a day, these services were unavailable, and there was nothing users could do except wait, or find alternatives.

Now imagine this happens to your AI API server. You've successfully deployed it to the cloud following Cloud Deployment, users are accessing it, and everything seems great. Then at 2 AM on a Saturday, something breaks. How long until users give up and try a competitor's service? How many will come back? In today's world where alternatives are just a Google search away, reliability is essential for survival.
Understanding High Availability
This is where availability comes in. It's the proportion of time your system is operational and ready when users need it. But "my system works most of the time" isn't a useful metric when you're trying to run a professional service. How do you measure availability objectively, and what targets should you aim for?
Measuring Availability
When you tell someone "my service is reliable," what does that actually mean? Does it fail once a day? Once a month? Once a year? And when it does fail, does it come back in 30 seconds or 3 hours? Without objective measurements, "reliable" is just a feeling. You can't promise it to users or improve it in an organized way.
The industry uses standard metrics to measure and talk about availability. Understanding these metrics helps you answer key questions: Is my system good enough for users? Where should I focus my efforts? How do I compare to competitors?
Mean Time Between Failures (MTBF)
The first metric tells you how long your system typically runs before something breaks.
Think of MTBF like a car's reliability rating. One car runs 50,000 miles between breakdowns, while another only makes it 5,000 miles. The first car has a much higher MTBF, which means it fails less frequently. The same concept applies to your AI service. Does it run for days, weeks, or months between failures?
MTBF is calculated by observing your system over time:
MTBF = Total Operating Time / Number of FailuresFor example, if your AI API server runs for 720 hours (30 days) and experiences 3 failures during that period:
MTBF = 720 hours / 3 failures = 240 hoursThis means on average, your system runs for 240 hours (10 days) between failures. The higher this number, the more reliable your system.
For AI systems specifically, failures might include model crashes, server running out of memory, dependency issues, network problems, or database corruption. Each of these counts as a failure event that reduces your MTBF.
Mean Time To Repair (MTTR)
MTBF tells you how often things break, but MTTR tells you how quickly you can fix them when they do.
MTTR measures your "time to recover" - in other words, from the moment users can't access your service until the moment it's working again. This includes detecting the problem, diagnosing what went wrong, applying a fix, and checking that everything works.
MTTR = Total Repair Time / Number of FailuresUsing our previous example, suppose those 3 failures took 2 hours, 1 hour, and 3 hours to fix:
MTTR = (2 + 1 + 3) hours / 3 failures = 2 hoursWhy does MTTR matter so much? Because modern research shows that downtime is very expensive. ITIC's 2024 study found that 90% of medium and large businesses lose over $300,000 for every hour their systems are down. Even for smaller operations, every minute of downtime means frustrated users, lost revenue, and damaged reputation.
For your AI API server, MTTR includes several steps. First, you notice something is wrong (through monitoring alerts or user complaints). Then you remote into your server and check logs. Next, you identify the root cause. Then you add the fix and check that it works. Finally, you confirm that users can access the service again. The faster you can complete this cycle, the lower your MTTR and the better your availability.
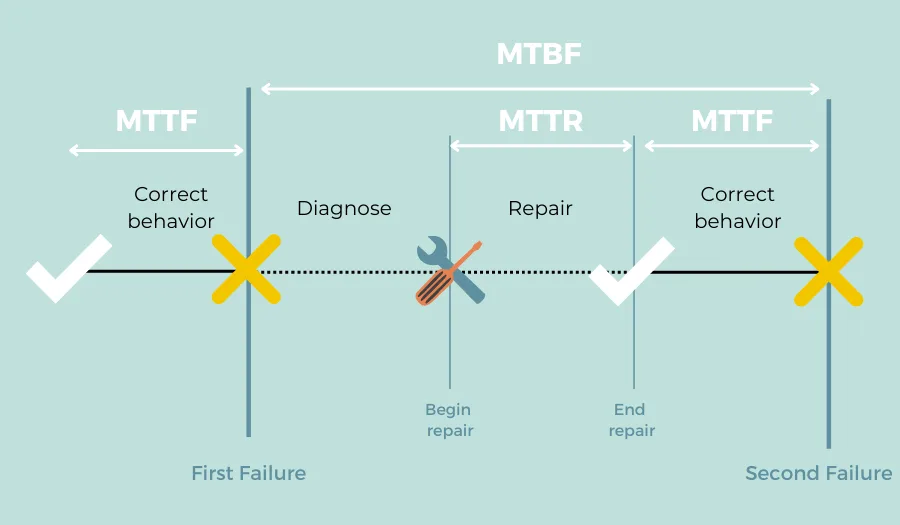
The Availability Formula
Here's where these metrics come together. Availability combines both how often failures happen (MTBF) and how quickly you recover (MTTR):
Availability = MTBF / (MTBF + MTTR) × 100%For example, suppose your AI API server has:
- MTBF = 240 hours (fails every 10 days on average)
- MTTR = 2 hours (takes 2 hours to fix on average)
Availability = 240 / (240 + 2) × 100%
= 240 / 242 × 100%
= 99.17%Your service has 99.17% availability, meaning it's operational 99.17% of the time.
This formula reveals a crucial insight about improving availability. You can either make failures rarer (increase MTBF) by writing better code, using more reliable hardware, or adding redundancy. Or you can recover faster (decrease MTTR) by implementing better monitoring, automating recovery processes, or having clear runbooks for common problems.
In fact, for many systems, improving MTTR gives you more bang for your buck. It's often easier to detect and fix problems faster than to prevent every possible failure.
Videos:
Extended Reading: To learn more about reliability metrics:
- Atlassian's Guide to Incident Metrics explains MTBF, MTTR, and related metrics used by modern software teams
- AWS: Distributed System Availability explores how availability metrics apply to distributed systems
Uptime Targets and SLAs
Now that you understand how to measure availability, you need to know what counts as "good." Is 99% availability impressive? Or unacceptably low? The industry has developed a standard vocabulary for talking about availability targets, centered around the concept of "nines."
The "Nines" System
Availability is usually expressed as a percentage with a certain number of 9s. More 9s mean better availability, but each additional nine becomes much harder and more expensive to achieve.
Here's what each level actually means in practice:
| Availability | Common Name | Downtime per Year | Downtime per Month | Downtime per Day |
|---|---|---|---|---|
| 99% | "Two nines" | 3.65 days | 7.2 hours | ~14.4 minutes |
| 99.9% | "Three nines" | 8.76 hours | 43.8 minutes | ~1.4 minutes |
| 99.99% | "Four nines" | 52.6 minutes | 4.4 minutes | ~8.6 seconds |
| 99.999% | "Five nines" | 5.3 minutes | 26 seconds | ~0.9 seconds |
In the industry, "five nines" (99.999% availability) is often called the gold standard. It sounds impressive to promise your users less than 6 minutes of downtime per year. Some critical systems, like emergency services, air traffic control, or financial trading platforms, really need this level of reliability.
But even Google's senior vice president for operations has publicly stated, "We don't believe Five 9s is attainable in a commercial service, if measured correctly." Why? Because achieving five nines requires several things. You need redundant systems at every level with no single points of failure. You need automatic failover mechanisms that work flawlessly. You need 24/7 monitoring and on-call engineering teams. You need geographic distribution to survive data center outages. And you need extensive testing and disaster recovery procedures.
The cost grows very quickly with each additional nine. Going from 99.9% to 99.99% might double your infrastructure costs. Going from 99.99% to 99.999% might triple them again. For most services, especially AI systems that aren't mission-critical, this investment doesn't make business sense.
The sweet spot for many professional services is 99.9% to 99.99%. This provides good reliability that users trust, without requiring the very high costs of five nines.
Service Level Agreements (SLAs)
Once you've decided on an availability target, how do you communicate this commitment to users? Enter the Service Level Agreement (SLA), a formal promise about what level of service users can expect.
An SLA typically specifies the availability target (like "99.9% uptime per month"), the measurement period for how and when availability is calculated, remedies for missing the target (refunds, service credits), and exclusions like planned maintenance windows or user-caused issues. For example, AWS's SLA for EC2 promises 99.99% availability. If they fail to meet this in a given month, customers receive service credits: 10% credit for 99.0%-99.99% availability, 30% credit for below 99.0%. This financial penalty motivates AWS to maintain high availability while providing compensation when things go wrong.
For your AI service, an SLA serves several purposes. It builds trust. Users need to know what to expect, and "we guarantee 99.9% uptime" is more reassuring than "we try to keep things running." It sets expectations. Users understand that some downtime is normal. If you promise 99.9%, users know that occasional brief outages are part of the deal. In a crowded AI market, a strong SLA can set you apart from competitors who make no promises. SLAs also give your team clear targets to design and operate toward.
Choosing the right SLA involves balancing user expectations with costs. A student project or internal tool might not need any formal SLA. A business productivity tool should promise at least 99.9%. Critical healthcare or financial AI applications might need 99.99% or higher. Also, it's better to promise 99.9% and consistently exceed it than to promise 99.99% and frequently fall short.
What Downtime Actually Costs
The Obvious Cost
When your service is down, you can't process requests. No requests means no revenue. For a simple AI API charging $0.01 per request and serving 1,000 requests per hour:
1 hour down = 1,000 requests lost × $0.01 = $10 lost
8.76 hours/year (99.9% uptime) = ~$88 lost per yearThat doesn't sound too bad, right? But this is just direct revenue, and for most services, it's actually the smallest part of the cost. Recent research reveals the true scale of downtime costs. Fortune 500 companies collectively lose $1.4 trillion per year to unscheduled downtime, which represents 11% of their revenue. For 41% of large enterprises, one hour of downtime costs between 1 million and 5 million. Industry-specific costs are even more dramatic. The automotive industry loses 2.3 million per hour (that's $600 per second). Manufacturing loses $260,000 per hour on average. Financial services and banking often see losses exceeding $5 million per hour. For smaller businesses, the numbers are smaller but still significant. A small retail or service business might lose 50,000 to 100,000 per hour, while even micro businesses can face losses around $1,600 per minute.
The Hidden Costs
Beyond immediate lost revenue, downtime creates ongoing costs that persist long after your service comes back online.
When users can't access your service, they don't just wait patiently. They Google for alternatives, sign up for competitor services, and might never come back. Acquiring new users is expensive. Losing existing ones because of reliability issues is especially painful because they've already shown they need what you offer. Word spreads fast. "That AI service that's always down" is a label that's hard to shake. In online communities, forums, and social media, reliability complaints get louder. Even after you fix underlying issues, the reputation lingers.
During and after outages, you'll face a flood of support tickets, refund requests, and angry emails. Your team spends time on damage control instead of building new features. These labor costs add up quickly. Happy users recommend services to colleagues and friends. Frustrated users don't. Every outage represents lost word-of-mouth growth and missed opportunities for positive reviews.
Extended Reading: To learn more about downtime impact:
- Siemens 2024 True Cost of Downtime Report analyzes how unscheduled downtime affects global companies
- The Impact of ChatGPT's 2024 Outages examines real-world effects when a major AI service goes down
Improving System Availability
Now you understand what availability means, how to measure it, and why it matters for your AI service. The natural next question is how you actually improve it.
The availability formula tells us there are two basic ways to improve availability. You can make failures less frequent (increase MTBF) or you can recover from failures faster (decrease MTTR). In practice, most high-availability strategies do both.
The core principle behind all availability improvements is simple: don't put all your eggs in one basket. If you have only one server and it crashes, everything stops; but if you have two servers and one crashes, the other keeps working. If you have only one copy of your database and it corrupts, your data is gone; but if you have backups, you can restore it and get back online.
In this section, we'll look at practical ways to make your AI system more reliable. We'll start by finding weak points in your architecture, places where a single failure brings everything down. Then we'll look at different types of redundancy you can add, from running multiple servers to keeping backups of your data. We'll also see how each strategy helps you recover faster when things go wrong.
Finding and Fixing Weak Points
Imagine you have a room lit by a single light bulb. If that bulb burns out, the entire room goes dark. Now imagine the same room with five light bulbs. If one burns out, you still have light from the other four. The room stays usable while you replace the broken bulb. The single-bulb setup has what engineers call a single point of failure (SPOF), which is one component whose failure brings down the entire system.
What is a Single Point of Failure?
A SPOF is any component in your system that, if it fails, causes everything to stop working. SPOFs are dangerous because they're often invisible until they actually fail. Your system runs fine for months, everything seems great, and then one day that critical component breaks and suddenly users can't access your service.
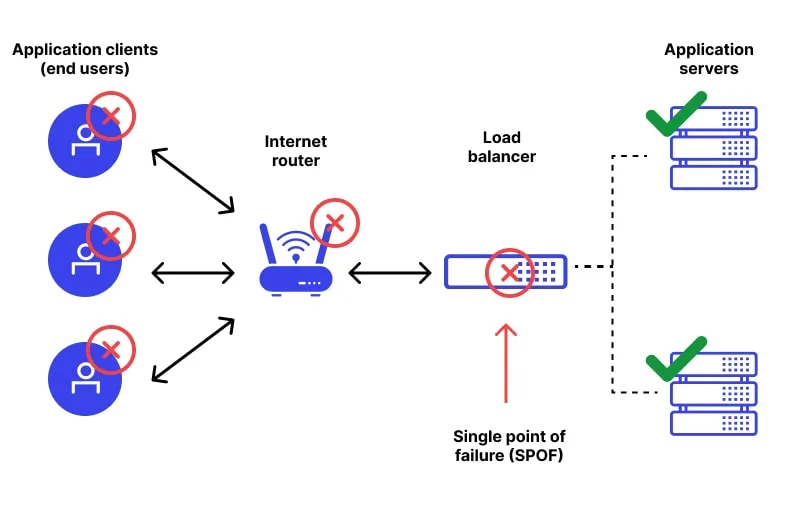
We can use the AI API server deployed in Cloud Deployment as an example to identify the potential SPOFs. If you're running everything on one virtual machine and it crashes (out of memory, hardware failure, data center issue), your entire service goes down. Users get connection errors and can't make any requests. If the database file gets corrupted (disk failure, power outage during write, software bug), you lose all your request history and any user data. The API might crash or return errors because it can't access the database. If the model file is deleted or corrupted, your API can still accept requests but can't make predictions. Every classification request fails. If the internet connection to your VM fails (ISP issue, data center network problem), users can't reach your service even though it's running perfectly. If your API calls another service (maybe for extra features) and that service goes down, your API might become unusable even though your own code is working fine.
Problem is, you might not even realize these are SPOFs until something goes wrong at 3 AM on a Saturday.
How to Identify SPOFs
The simplest way to find SPOFs is to walk through your system architecture and ask "what if this fails?" for every component.
Let's do this for your AI API server. What if my VM crashes? Entire service goes down. Users get connection timeouts. This is a SPOF. What if my database file corrupts? All user data lost, API probably crashes or errors. This is a SPOF. What if I delete my model file accidentally? API runs but can't make predictions. This is a SPOF. What if my Docker container crashes? If you configured --restart unless-stopped, it automatically restarts in seconds. Users might see brief errors during restart, but service comes back. Partial SPOF, but with quick recovery. What if the cloud provider's entire region goes offline? Everything in that region goes down, including your VM. This is a SPOF.
Drawing your architecture can make this easier. Sketch out the components (VM, container, database, model, load balancer if you have one) and the connections between them. Look for any component that doesn't have a backup or alternative path.
Two Ways to Handle SPOFs
Once you've identified a SPOF, you have two options. You can eliminate it or plan to recover from it quickly. The right choice depends on how critical the component is and how much you're willing to invest.
One option is to eliminate the SPOF through prevention. This means adding redundancy so that failure of one component doesn't matter. If you have two servers instead of one, the failure of either server doesn't bring down your service. The other one keeps working. This is the "increase MTBF" approach where you haven't made individual servers less likely to fail, but you've made your overall system less likely to fail. For example, instead of one VM, deploy your AI API on two VMs with a load balancer in front. When one VM crashes, the load balancer automatically sends all traffic to the other VM. Users might not even notice the failure. This makes sense when the component is critical, failures are relatively common, you can afford the extra cost, and you need high availability.
Another option is to plan for quick recovery and accept a faster MTTR. This means accepting that the SPOF exists, but preparing to fix it as fast as possible when it fails. You keep backups, write clear recovery procedures, and maybe practice restoring to make sure you can do it quickly. This is the "decrease MTTR" approach where failures still happen, but you minimize how long they last. For example, your database file is a SPOF. Instead of setting up complex database replication, you run automated daily backups to cloud storage. When the database corrupts, you have a clear procedure. Download the latest backup, replace the corrupted file, restart the container. Total recovery time is maybe 30 minutes. This makes sense when the component is expensive or complex to duplicate, failures are rare, you can tolerate some downtime, and quick recovery is feasible.
For a student project or class assignment aiming for 99% uptime, don't worry about eliminating every SPOF. Focus on quick recovery plans, keep good backups of your database, and document how to redeploy if your VM dies. Cost is nearly free, and acceptable downtime is measured in hours. For a business tool or production service targeting 99.9% uptime, eliminate critical SPOFs by running on multiple servers. Have quick recovery plans for expensive components, set up automated backups every few hours, and consider database replication for critical data. Cost is moderate and acceptable downtime is minutes to an hour. For a critical system requiring 99.99%+ uptime, you will have to eliminate SPOFs at all levels. Deploy multiple servers in different geographic regions, implement real-time database replication, and set up automated failover mechanisms. Cost is high and acceptable downtime is seconds to minutes.
Videos:
Extended Reading: To learn more about SPOF identification and elimination:
- [What is a Single Point of Failure?](https://www.techtarget.com/searchdata center/definition/Single-point-of-failure-SPOF) from TechTarget provides full coverage
- System Design: How to Avoid Single Points of Failure offers technical strategies with practical examples and diagrams
- How to Avoid Single Points of Failure provides practical strategies and tools
Redundancy and Backups
We've identified where your system is at risk. Now let's talk about how to protect it. The solution comes in two related forms: running backups (redundancy) prevents downtime, and saved backups (snapshots) enable quick recovery.
Think of redundancy like having a spare key to your house. If you lose your main key, you don't have to break down the door. You just use the spare and life continues normally. Backups, on the other hand, are like having photos of everything in your house. If there's a fire, the photos don't prevent the disaster, but they help you rebuild afterward.
Both are valuable. Redundancy keeps your service running when components fail. Backups help you recover when disasters strike. Let's explore how to set up both for different parts of your AI system.
Hardware-Level: Multiple Servers
Instead of running your AI API on a single cloud VM, you run it on two or more VMs simultaneously. A load balancer sits in front, distributing incoming requests across all healthy servers. When one server crashes, the load balancer stops sending traffic to it and routes everything to the remaining servers, and your API keeps responding to requests. Users might not even notice the problem. That's the beauty of redundancy, that your service keeps running and you can fix the failed server later.
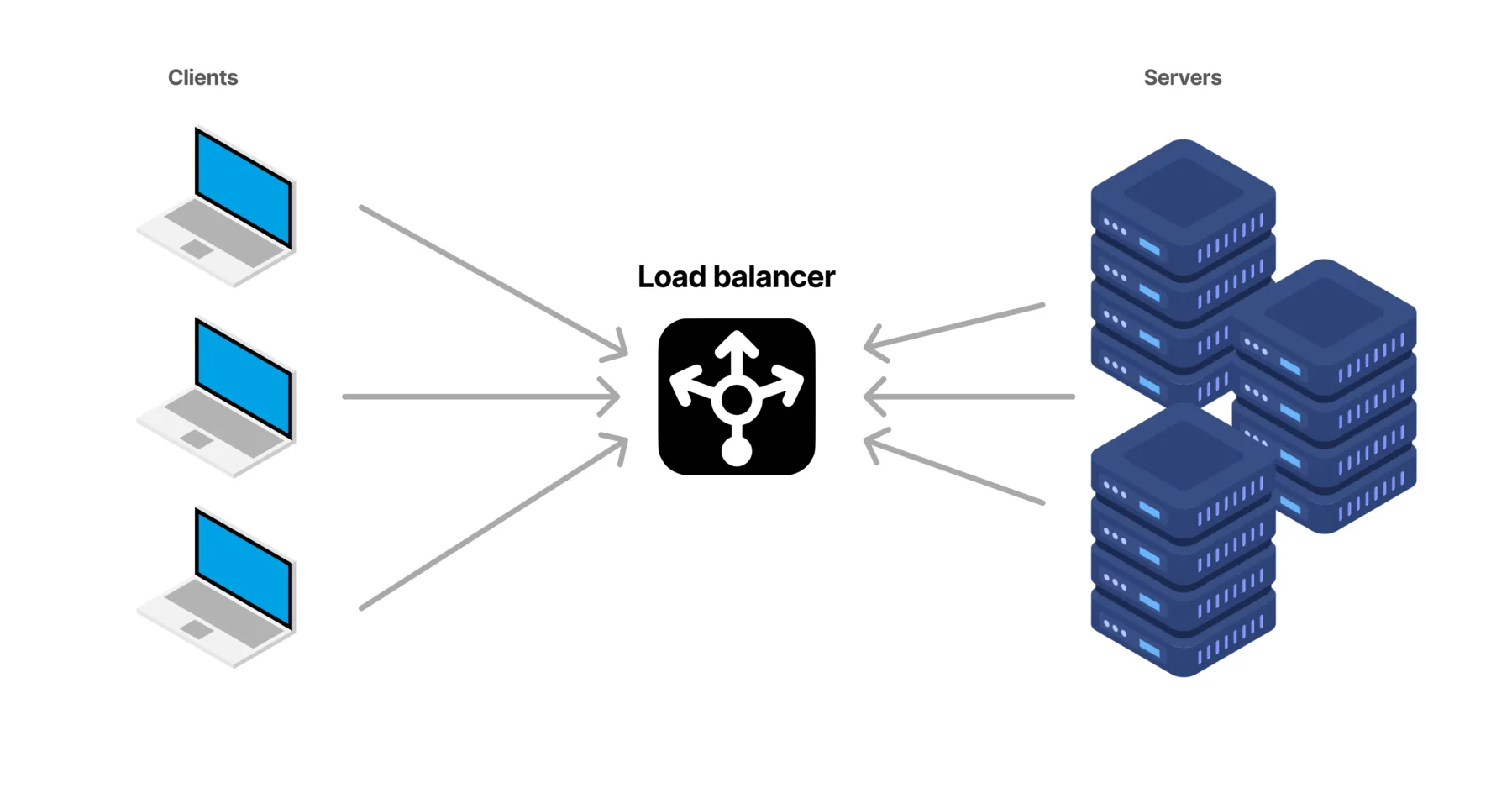
Suppose you currently run your containerized API on one cloud VM. Here's how to add hardware redundancy. Deploy the same Docker container on a second VM, maybe in a different availability zone or even region. Set up a load balancer using Nginx, cloud load balancers (like AWS ELB), or simple DNS round-robin. Configure health checks so the load balancer pings each server periodically (like GET /health). If a server doesn't respond, traffic stops going to it. If your API is stateless (each request independent), this just works. If you store state, you'll need shared storage or session replication.
Running two servers costs roughly twice as much as one. But for 99.9% availability targets, this investment often makes sense. Use this approach when you need 99.9%+ availability, can afford 2x compute costs, individual server failures are your biggest risk, and traffic volume justifies multiple servers.
Software-Level: Multiple Containers
Instead of running one Docker container with your AI API, you run multiple containers simultaneously, possibly all on the same VM. When one container crashes, the others keep serving requests.
Container crashes are common, specific causes include memory leaks, unhandled exceptions, and resource exhaustion. Running multiple containers means one crashing doesn't take down your whole service. Docker's restart policies automatically bring crashed containers back online. While it's restarting, other containers can handle the traffic.
You learned in Packaging & Containerization to run your API with docker run. Here's how to run three instances for redundancy:
# Start three containers of your AI API
docker run -d -p 8001:8000 --restart unless-stopped --name ai-api-1 my-ai-classifier:v1.0
docker run -d -p 8002:8000 --restart unless-stopped --name ai-api-2 my-ai-classifier:v1.0
docker run -d -p 8003:8000 --restart unless-stopped --name ai-api-3 my-ai-classifier:v1.0
# Set up Nginx to load balance across them
# (Nginx config distributes traffic to localhost:8001, :8002, :8003)Now if ai-api-2 crashes, ai-api-1 and ai-api-3 continue serving requests. Docker will also automatically restart ai-api-2. The --restart unless-stopped flag is also important here. It tells Docker to automatically restart the container if it crashes, but not if you manually stopped it.
Running multiple containers on one VM is relatively cheap. You just need enough memory and CPU to handle all containers, which makes it much more affordable than multiple servers. Use this approach even for moderate availability targets (99%+), especially when application-level failures are common.
Data-Level: Backups and Replication
Data is special. When hardware fails, you buy new hardware. When software crashes, you restart it. But when data is lost, corrupted, deleted, or destroyed, it might be gone forever. Your users' data, request history, and system state represent irreplaceable information. Protecting data requires different strategies than protecting hardware or software, and usually involves backups and replication.
Backups are periodic snapshots of your data saved to a safe location. They're like save points in a video game. If something goes wrong, you can reload from the last save. Backups don't prevent failures, but they enable you to recover from them.
For your AI API with a SQLite database, below is an example how you can automatically backup the database:
#!/bin/bash
# Simple backup script that runs daily via cron
# Create timestamped backup
BACKUP_FILE="backup-$(date +%Y%m%d-%H%M%S).tar.gz"
tar -czf $BACKUP_FILE /app/data/ai_api.db
# Upload to cloud storage (AWS S3 example)
aws s3 cp $BACKUP_FILE s3://my-backups/ai-api/
# Keep only last 7 days locally to save space
find /backups -name "backup-*.tar.gz" -mtime +7 -deleteSet this to run automatically at 2 AM every day, and now if your database corrupts at 3 PM, you have a recent backup from 2 AM. When you need to recover, download the latest backup from S3 (aws s3 cp s3://my-backups/ai-api/backup-20250126-020000.tar.gz .), extract it (tar -xzf backup-20250126-020000.tar.gz), replace the corrupted database (mv ai_api.db /app/data/ai_api.db), restart your container (docker restart ai-api), and verify the service is working. Total recovery time is about 15-30 minutes, depending on backup size, download speed. This is your MTTR for database corruption. Also, you will lose data created between 2 AM (last backup) and when corruption happened. More frequent backups reduce data loss but consume more storage and resources.
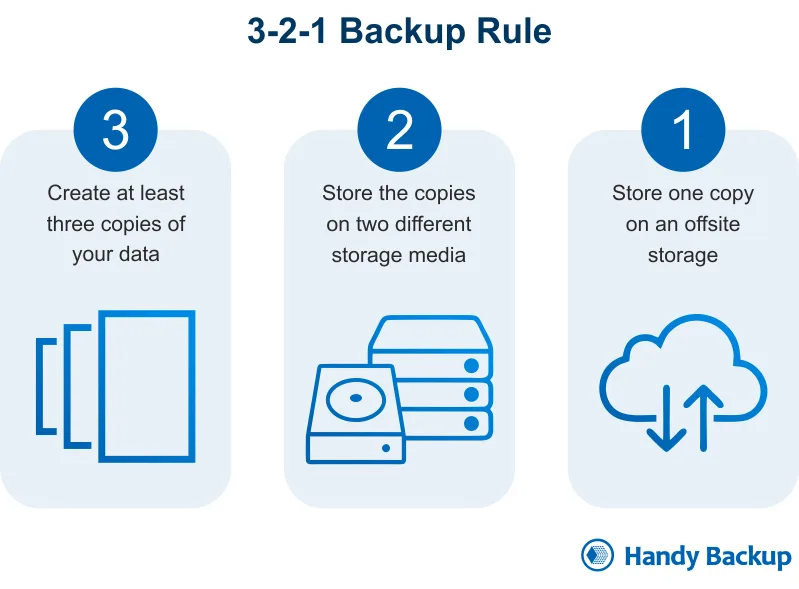
Security experts recommend the 3-2-1 rule for critical data. Keep 3 copies of your data (original plus two backups), on 2 different storage types (like local disk plus cloud storage), with 1 off-site backup (survives building fire, flood, or local disaster). For your AI API, this might look like keeping your original SQLite database on your cloud VM (/app/data/ai_api.db), a daily snapshot on the same VM but different disk/partition, and another daily snapshot uploaded to cloud storage (like AWS S3 or Google Cloud Storage). This protects against several scenarios. If you accidentally delete something, restore from Backup 1 on the same VM (very fast). If a disk fails, restore from Backup 2 in cloud storage (a bit slower). If your VM is terminated, restore from Backup 2 and rebuild the VM. If an entire data center fails, Backup 2 is in a different region and remains accessible. The cloud storage backup is particularly important. If your entire VM is deleted (you accidentally terminate it, cloud provider has issues, account compromised), your local backups disappear too. Cloud storage in a different region survives these disasters.
Backups enable recovery (they reduce MTTR). But replication prevents downtime in the first place (it increases MTBF). With replication, you maintain two or more copies of your database that stay continuously synchronized. How does it work? The primary database handles all write operations (create, update, delete). Replica databases continuously receive updates from the primary and stay in sync. Replicas can handle read operations, spreading the load. If the primary fails, you promote a replica to become the new primary.
For your AI API, you might upgrade from SQLite (single-file database) to PostgreSQL with replication:
Primary PostgreSQL (VM 1) ←→ Replica PostgreSQL (VM 2)
↓ ↓
Handles writes Handles reads + standbyWhen the primary fails, your application detects the failure (connection timeout), switches to the replica (either manually or automatically), promotes the replica to primary, and service continues with minimal disruption. For this setup, recovery time is seconds to minutes with automatic failover, instead of the 15-30 minutes needed to restore from backups. Data loss is minimal, only transactions in the last few seconds before failure. As you can tell, compared to backups, replication has much better MTTR, but more complex to set up and maintain, higher cost (need to run multiple database servers), and requires application changes (connection pooling, failover logic).
| Approach | MTTR | Data Loss | Complexity | Cost | Best For |
|---|---|---|---|---|---|
| Daily backups | Hours | Up to 24h | Low | Very low | 99% uptime |
| Hourly backups | 30-60 min | Up to 1h | Low | Low | 99% uptime |
| Replication | Seconds-minutes | Minimal | High | Medium-high | 99.9%+ uptime |
Videos:
Extended Reading: To learn more about redundancy and backup strategies:
- High Availability System Design from Cisco provides full coverage of redundancy concepts
- Redundancy and Replication Strategies explores different approaches with practical examples
- Backup and Disaster Recovery Best Practices offers 15 essential practices for protecting your data
Popular backup tools to implement the strategies discussed:
- Litestream for SQLite and pgBackRest for PostgreSQL offer database-specific backup with cloud storage support
- Restic and BorgBackup provide general-purpose backup with deduplication and encryption